
Viviamo in tempi senza precedenti in cui, grazie alla tecnologia, chiunque – persona o azienda – può finalmente iniziare a sfruttare i dati per migliorare la sua vita o le sue operazioni, attraverso la Data Science.
Come mai prima d’ora, oggi abbiamo accesso ad un’enorme quantità di dati e informazioni che sta solo aspettando di essere analizzata ed interpretata, con l’aiuto di un insieme ormai maturo e diffuso di sistemi metodici.
Non approfittare di questa opportunità è un grosso rischio, poiché darà la possibilità alla concorrenza di fare un passo in avanti.
Proliferazione dei dati e super computer: la tempesta perfetta
Perché ora? Per due motivi: la creazione di dati è esplosa negli ultimi 10-15 anni e ora abbiamo una potenza di calcolo semplicemente inimmaginabile appena 5 anni fa.
Ecco alcuni esempi per capire meglio.
Proliferazione dei dati
Parlando di creazione di dati, nel 2010 all’evento Techonomy, Eric Schmidt (CEO di Google) ha menzionato questo fatto sorprendente: “dagli albori della civiltà fino al 2003, sono stati creati 5 exabyte di informazioni; oggi (nel 2010, ndr), la stessa cifra viene creata ogni due giorni”. (https://youtu.be/UAcCIsrAq70).
Schmidt non era poi così tanto lontano dalla realtà. Un rapporto di IBM dell’anno scorso sembrava confermare queste stime per l’anno 2016 (https://www.iflscience.com/technology/how-much-data-does-the-world-generate-every-minute/). Nel 2018 stiamo già assistendo a stime intorno ai 4-5 exabyte al giorno. Per vederlo da un’altra prospettiva, circa il 90% di tutte le informazioni del mondo è stato creato solo negli ultimi due anni. E questa tendenza sta accelerando: alcune stime prevedono che la tendenza alla creazione dei dati aumenterà fino a 40 volte negli anni 2020-2022.
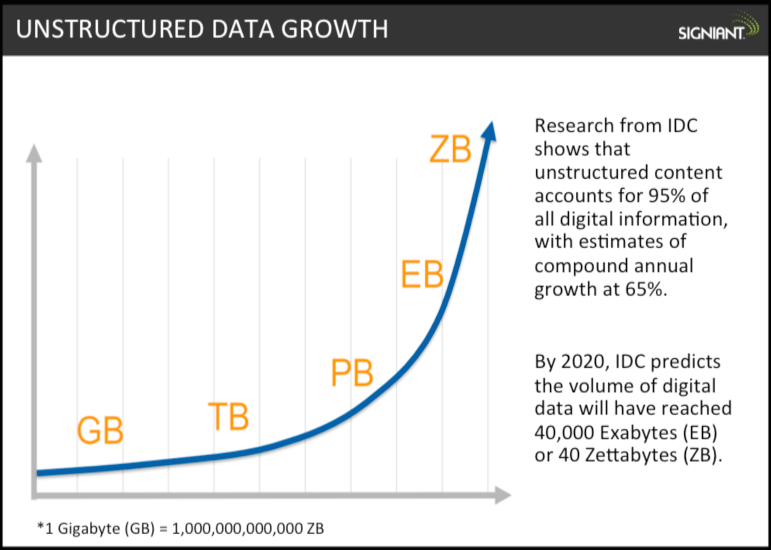
Mentre potrebbe essere divertente continuare a condividere questi enormi numeri e curiosità sensazionali, forse dovrebbe essere presa nota del perché questo sta accadendo ora.
La maggior parte penserà subito, giustamente, a Internet ed alle esplosioni dei social media e dei contenuti generati dai consumatori. Certamente questi hanno giocato un ruolo importante, e in effetti riceviamo moltissimi nuovi fantastici contenuti dai post di Facebook, dai video su YouTube e dalle foto su Instagram. Ma questa è solo la punta dell’iceberg dei contenuti.
Oggi, tuttavia, i dati vengono creati in larga parte automaticamente da miliardi di dispositivi tecnologici in tutto il mondo (e oltre).
I sensori su ogni smartphone, GPS su auto e camion, telecamere a circuito chiuso, dispositivi Internet-of-Things, simulatori di banche di tendenze azionarie e di mercato e qualsiasi dispositivo elettronico, genereranno (e condivideranno) una quantità significativa di informazioni che può essere usato da noi o da altri.
Super computer
Se da un lato abbiamo letteralmente perso il controllo su quali (e quanti) dati vengono creati in ogni secondo in tutto il mondo, dall’altro possiamo fare affidamento su una capacità di elaborazione senza precedenti (e, senza girarci intorno, non si tratta di una capacità umana).
I nostri cari computer stanno assumendo talmente un ruolo guida nella raccolta, nell’organizzazione e nell’elaborazione dei dati, che abbiamo chiesto ad altre macchine di crearne in abbondanza.
Mentre analisti e scienziati stanno diventando più audaci nell’ammettere che le previsioni di Moore (la cosiddetta “Legge di Moore”) potrebbero sembrare più anacronistiche, i computer fino ad oggi hanno fatto la loro parte.
Grazie ai continui miglioramenti tecnici – sia hardware che software – negli ultimi 20-30 anni, i computer possono ancora gestire la crescita esponenziale dei dati che ricevono lato software, ed elaborarli in modo significativo.
Inoltre, servizi come Amazon Web Services, Google Cloud e altri, consentono a chiunque di accedere alla potenza di elaborazione necessaria, in qualsiasi momento e per qualsiasi scopo.
In breve, la “tempesta perfetta” è finalmente arrivata e stiamo navigando proprio verso il suo nucleo. Rischiamo di perdere il controllo della nostra “barca” in questa tempesta? Se non ci prepariamo per questo, sicuramente lo perderemo.
Ma, se stai leggendo questo post, stai facendo la tua parte per imparare a navigare in questo nuovo tempo.
Che cos’è la Scienza dei Dati?
Il modo migliore per capire cosa sia la Scienza dei Dati è farlo considerandola come l’intersezione tra matematica (e suoi algoritmi), informatica e le competenze necessarie nel settore specifico in cui deve essere implementato.
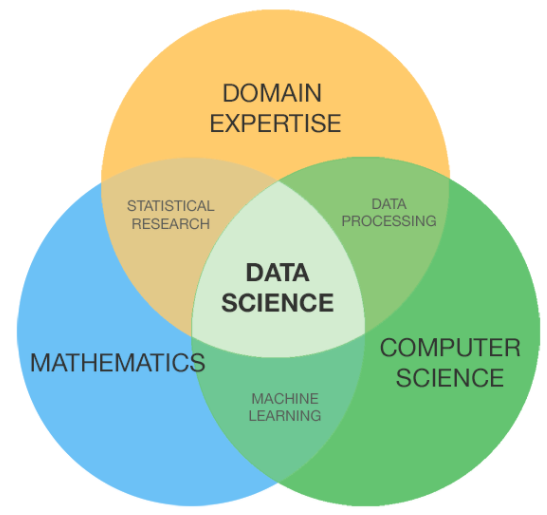
Stai facendo delle operazioni in un’azienda? Allora è necessario istruire i computer (informatica) con algoritmi specifici (matematica) su come analizzare i rapporti di produzione raccolti dalle macchine al fine di bilanciare le linee di produzione (competenza del settore).
Gestisci un’agenzia pubblicitaria? Allora devi utilizzare piattaforme di analisi proprietarie o di altra tipologia (informatica) e determinare quali sono i migliori KPI da monitorare (matematica) al fine di monitorare l’efficacia della pubblicità sulle tue campagne digitali (competenza del settore).
Il processo inizia raccogliendo dati (strutturati o non strutturati) da molte fonti e in diverse forme, per poi organizzarli sotto forma di conoscenza e quindi interpretarli. Se un’organizzazione è in grado di padroneggiare Data Science in questo modo, avrà un vantaggio competitivo significativo nell’età di oggi.
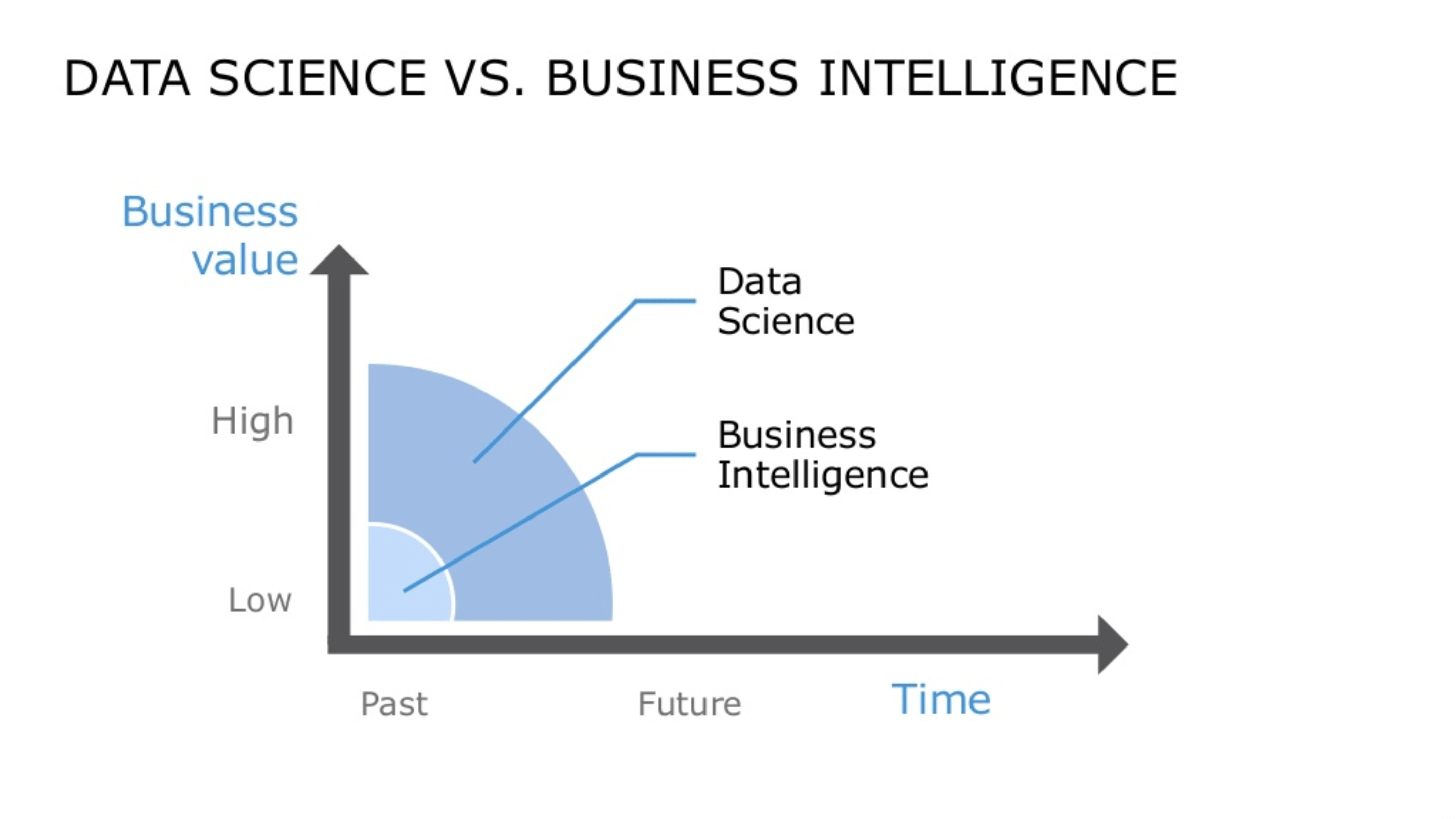
Questa non è una nuova attività. Le aziende lo fanno da almeno 30 o 40 anni, con la loro divisione di Business Intelligence (o unità equivalenti).
Ciò che sta cambiando le regole del gioco è la quantità e il tipo di dati disponibili. Questa nuova fase di creazione e disponibilità di dati si chiama “Big Data” e i Big Data vengono analizzati al meglio tramite Data Science.
Ci sarebbe molto da dire su cosa siano realmente i “Big Data”, su come rilevarli, identificarli, organizzarli ed elaborarli, ma lasceremo questi argomenti per un nuovo post.
Qui vogliamo concentrarci sulle giuste mosse per iniziare a trarre vantaggio da questo settore.
Come le aziende possono trarre vantaggio dalla scienza dei dati
OPERAZIONI E CLIENTI
Se non hai ancora iniziato ad aggiornare la tua azienda in questo campo e nel suo approccio gestionale, è il momento di recuperare. Applicazioni e vantaggi sono praticamente illimitati.
Oggigiorno le applicazioni Big Science sono applicabili in qualsiasi operazione di qualsiasi organizzazione, mercato o azienda. Apprendere come raccogliere i dati che contano, e saper interpretarli, può aiutarti in due modi: aumentare il tuo business e accrescere i tuoi profitti.
Puoi potenziare il tuo business in modo da rendere più efficaci le tue attività di sviluppo: misura i tassi di conversione, l’efficacia delle campagne di marketing, la soddisfazione dei clienti e così via.
Puoi anche aumentare i profitti, conoscendo esattamente quale tipo di cliente pagherebbe per quale prodotto.
Inoltre, imparando ad ottimizzare le tue operazioni potrai capire dove tagliare eventuali costi, come aumentare produzione e resa, in che modo rendere più efficiente la catena di approvvigionamento e tanti altri aspetti migliorativi.
Le applicazioni di Data Science sono letteralmente illimitate. Come diceva Peter Drucker: “Se riesci a misurarlo, puoi migliorarlo!“… e, oggi, misuriamo quasi tutto ciò che possiamo pensare.
IN PRIMIS, CULTURA DEI DATI
Se sei seriamente intenzionato ad aggiornare la tua azienda, o il tuo business, dando alla Data Science l’importanza che merita, per prima cosa devi lavorare sulla cultura di tale organizzazione. Il cambiamento non avverrà se le persone non sono aperte e pensano che non sarà un miglioramento per tutti.
La cultura interna sul tema della Data Science è di fondamentale importanza: prima di poter fare qualcosa con i dati, è necessario capire cosa stai facendo e perché lo fai.
È certamente un progresso in corso e ogni nuova lettura o video è di aiuto.
I migliori istituti di istruzione (tra cui Stanford, Harvard e molti altri in tutto il mondo) adesso offrono interi percorsi di studio. Se non hai tempo per tornare a scuola a tempo pieno, allora dovresti cercare altre opportunità di apprendimento. Certamente il web può aiutare molto. Di seguito, nella sezione di riferimento, siamo felici di condividere alcune risorse che riteniamo estremamente utili per iniziare.
Il secondo passo è sicuramente quello di ottenere le risorse in grado di consentire questo cambiamento culturale all’interno della tua organizzazione.
Le risorse di cui hai bisogno (e che non devono necessariamente essere possedute o controllate dalla tua azienda) sono persone, strumenti (hardware e software) e, naturalmente, dati (quelli giusti e tanti).
RISORSE: PERSONE, DATI E STRUMENTI
PERSONE
Qualcuno del tuo team, o tu stesso, dovrà guidare questa trasformazione culturale interna.
Quella persona sarà il primo avvocato responsabile della Data Science nel team. Tutto parte da questa persona. Non ha bisogno di essere un esperto nel settore, ma sicuramente deve avere una buona comprensione del valore che la Data Science può apportare all’azienda o alle operazioni. Sarà il primo “sponsor”. Inoltre, questa figura guiderà il team di Data Science, non appena l’organizzazione sarà in grado di procedere.
La creazione di un team dedicato alla Data Science richiederebbe un post a parte.
La scienza dei dati, se ben eseguita, richiede un insieme di competenze difficili (forse anche impossibili) da trovare in un singolo individuo. Sicuramente una figura chiave è quella del Data Scientist, considerata oggi una delle figure di lavoro più “sexy” (vedi l’articolo in basso).
In questa immagine istruttiva trovi le principali abilità che dovrebbero essere trovate in un Data Scientist. Non è un profilo facile da cercare, eh?
Ma, anche nel fortunato caso di trovare il candidato perfetto, un singolo Data Scientist non sarebbe in grado di compiere la “magia” necessaria nella tua organizzazione.
Avrai probabilmente bisogno di ingegneri del software, esperti di piattaforme (strumenti di cui parleremo in alcuni paragrafi), amministratori di sistema, matematici e statistici (che si concentreranno sugli algoritmi) e, infine, esperti di business intelligence che capiranno come interpretare il risultati e quali azioni suggerire al management per trarre vantaggio da queste nuove pratiche.
Non farti prendere dal panico! Iniziamo con i primi passi.
Dal momento in cui l’organizzazione deciderà di investire in Data Science, la palla inizierà a rotolare e il processo partirà. Si può quindi decidere di costituire immediatamente un team interno con tutte le risorse necessarie o di lavorare con altre società o individui.
DATI
Non appena trovate le figure adatte, sarà il momento di valutare a quali dati può accedere l’organizzazione e quale valore potrebbe potenzialmente essere estratto da essi.
Anche se nelle prime fasi il valore che potrebbe essere estratto dai dati disponibili sarà supposto, sarà comunque un importante punto di partenza. L’analisi effettiva dei dati basata sulle ipotesi formulate avvierà il processo. Da quel momento in poi, saranno iterazioni e interpretazioni continue.
STRUMENTI
Infine, la terza risorsa chiave è avere un set di strumenti in grado di elaborare i dati e, quindi, perfezionare gli algoritmi che deciderai di utilizzare per analizzarli.
Avrai bisogno di qualsiasi cosa, dalle unità di archiviazione alle potenti CPU: se sei una piccola/media impresa, fortunatamente puoi trovare diverse soluzioni su Cloud, come Saas (Software-as-a-Service) o PaaS (Platform-as- a-Service).
Avrai bisogno di software e strumenti specifici (Hadoop, AWS, Cloudera, MongoDB, Google BigQuery, Hive, Spark, ecc.) e di qualcuno per padroneggiarli.
Ricorda sempre: questi sono solo strumenti! Non considerare nemmeno di prenderne uno di essi (a proposito, possono essere piuttosto costosi) se non hai già deciso quale team ci lavorerà e quale tipo di dati (disponibili) verranno elaborati.
In sintesi: hai bisogno di persone (quelle giuste!), dati e strumenti per iniziare in questo settore. Per cui è necessario avviare le operazioni coordinando e bilanciando sempre queste 3 tipologie di risorse. Se non si spuntano queste caselle, sarà difficile avere una preziosa operazione di Data Science all’interno della propria organizzazione.
ESTERNALIZZARE O COSTRUIRE ALL’INTERNO DELL’ORGANIZZAZIONE
La questione se esternalizzare o costruire un team all’interno dell’organizzazione si presenta ovviamente fin da subito. Purtroppo, però, non esiste una soluzione unica per tutti.
Alcune aziende investiranno immediatamente per avere tutto all’interno, mentre altre opteranno per approcci meno pesanti in termini di investimenti, che potrebbero essere meno rischiosi a breve termine, ma forse più pericolosi strategicamente.
In base alla strategia della tua azienda, potresti voler esternalizzare alcune parti del processo. Spesso le organizzazioni tendono ad esternalizzare la raccolta, l’archiviazione e l’elaborazione dei dati. Meno spesso, e possiamo comprendere le ragioni strategiche alla base di questa decisione, l’interpretazione dei risultati dell’analisi dei dati avviene all’interno dell’organizzazione.
Nel tempo, man mano che l’organizzazione acquisisce know-how nel campo della Data Science, il numero di compiti aumenta internamente, esternalizzando quelli più meccanici e meno strategici.
—
Se vuoi contattarci per una conversazione o per saperne di più su ciò che facciamo, saremo felici di conoscerti. Contattaci a info@exafutures.com e ti risponderemo il prima possibile.
—
Note:
- Data Science (Wikipedia): https://en.wikipedia.org/wiki/Data_science
- 10 Key Marketing Trends in 2017 (IBM): https://www-01.ibm.com/common/ssi/cgi-bin/ssialias?htmlfid=WRL12345USEN
- How Much Data does the World Generate Every Minute (IFLScience): https://www.iflscience.com/technology/how-much-data-does-the-world-generate-every-minute/
- Data Scientist – The Sexiest Job of the 21st Century (Harvard Business Review): https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
- The 9 Best Free Online Big Data and Data Science Courses: https://www.forbes.com/sites/bernardmarr/2017/06/06/the-9-best-free-online-big-data-and-data-science-courses
- Erik Schmidt at Techonomy 2010: https://youtu.be/UAcCIsrAq70
- Re-interpreting Moore’s Law (Electrical Engineering Journal): https://www.eejournal.com/article/re-interpreting-moores-law/

